wims
Double Eagle Member
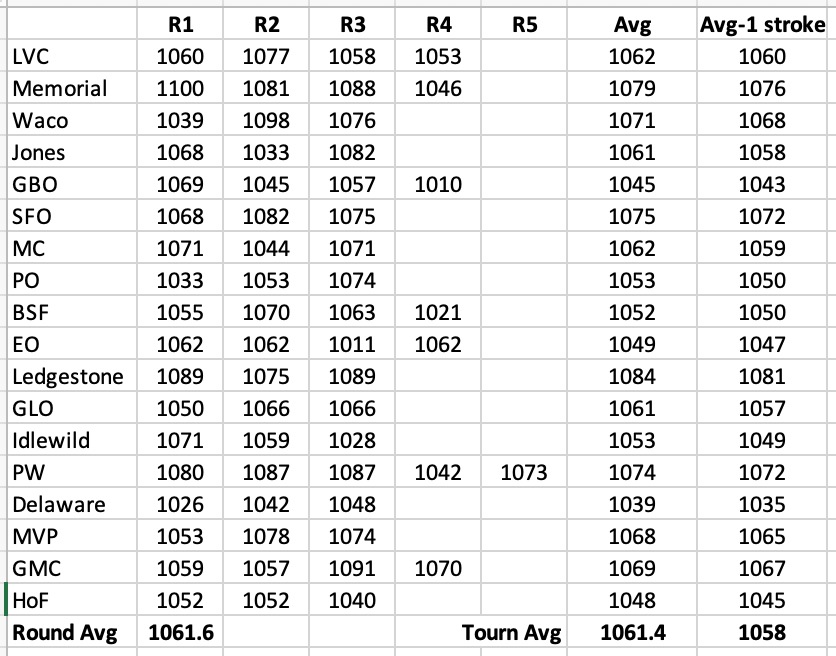
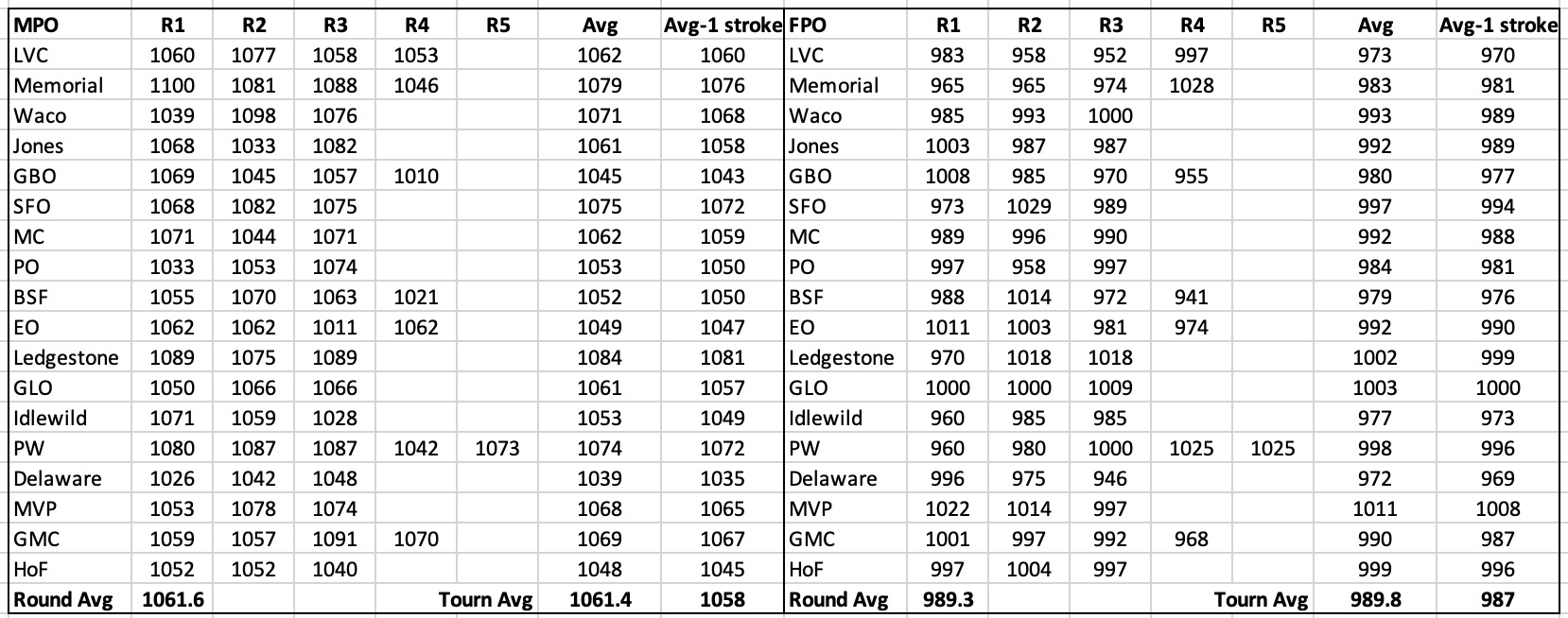
I think you need to brush up on your maths on this one. What sort of maths do you believe calculates what the SSA or 1000 rated score is? Do you think it's calculated from thin air?
...
Cgkdisc is working for the PDGA as the official who rates rounds. He is the most qualified person in the world when it comes to rating a round and he knows perfectly well what maths determines what a 1000 rated round is, because it is in fact *his* analysis that is determining rating